.jpg)
.jpg)
.jpg)
Мы продолжаем цикл статей о скриптах в издательских пакетах Adobe. Ранее были рассмотрены основные подходы в скриптинге для Illustrator, на очереди — автоматизация рабочих процессов в InDesign.
Если интенсивнее работать уже невозможно, начни работать умнее.
Афоризм из ИнтернетаСтатья посвящена форматированию текста согласно принятым правилам типографики (расстановка неразрывных пробелов и прочих спецсимволов), что актуально для всех верстальщиков. Предлагаемое решение работает быстро, легко настраивается и является хорошей альтернативой коммерческим разработкам.
Теория
Проблемы поиска/замены в Indesign | Поскольку я занимаюсь вёрсткой изданий экономической направленности, изобилующих цифрами и сокращениями, а возможности InDesign в части поиска и замены довольно скромны (несмотря на внушительных размеров диалоговое окно), возникла острая необходимость обойти ограничения программы. Проблема в том, что InDesign не позволяет менять фрагменты по гибкой маске (например, заменять слова, начинающиеся с определённых символов) — только чётко определённый фрагмент на другой. Например, нельзя заменить сочетание «цифра-тире-цифра» — на «цифра-неразрывное тире-цифра», «цифра-пробел» — на «цифра-неразрывный пробел». Примеров таких полезных замен множество…
Поиск в Интернете готовых решений дал всего один результат, который, к сожалению, не решал всех проблем. По сути, он представлял собой огромную (на несколько сот строк) перекодировочную таблицу: в каждой строке сначала указывалось, что искать, потом — на что менять, и так для каждой буквы алфавита для каждой комбинации со спецзнаками (работает на основе встроенного механизма InDesign). Добавление в эту таблицу своих правил — дело непростое в силу её громоздкости. Поэтому было решено пойти другим путём — использовать возможности поиска, встроенные в JavaScript. Кстати, впоследствии созданный простенький скрипт трансформировался в полноценную утилиту по гибкому поиску/замене любых сочетаний.
Регулярные помощники | Для операций поиска/замены в JavaScript предусмотрено использование т. н. «регулярных выражений» — комбинаций спецсимволов (подстановочных знаков), с помощью которых реализуется поиск по заданному шаблону. Например, любой цифре соответствует шаблон [0-9], текстовому символу — [а-я], если нужно включить и прописные буквы, [а-яА-Я] и т. д. Вообще же, в диапазон поиска можно включать любой символ, нужно лишь помнить об особом предназначении знаков +?*|^\ и точки.
Знак вопроса говорит о том, что символ может присутствовать, но не обязательно (т. е. результатом поиска по шаблону «шее?» в «длинношеее» будет «ше» и «шее»), «плюс» — в тексте должно быть хотя бы одно совпадение предыдущего символа («ше+» даст «ше», «шее» и «шеее»). Действие «звёздочки» похоже на «плюс», но охват шире: «ше*» найдёт, кроме «ше» и «шее», также «ш» и «шеее». Символ «|» — аналог операции «или»: [ко|ит] эквивалентно поиску «кот» и «кит». Чтобы искать «ко» и «ит» одновременно, потребуется (как вариант) использовать скобки: (ко)|(ит). «Крышка» имеет разный смысл в зависимости от местонахождения. Если в начале шаблона искомый фрагмент ищется только в начале строки, внутри диапазона — диапазон присутствовать не должен (т. е. по [^а-я] найдётся всё, кроме знаков алфавита, а [^0-9] найдёт всё, что не является цифрой).
Слэш зарезервирован для специальных случаев; один из них — поиск спецзнаков \t, \r, \n (знак табуляции, символ абзаца и новая строка). Перед ними ставят ещё один знак «\», т. е. строка поиска будет \\t и \\r, соответственно. Точка используется для поиска любого знака («длин.+» найдёт не только все слово «длинношеее», но и все оставшиеся слова до конца строки). При поиске удобно пользоваться группировкой (заключать в скобки части поискового выражения), что даёт дополнительную гибкость при операциях замены.
Мы рассмотрели подстановочные знаки для поиска. Замена имеет свою специфику. Для последующего использования найденных фрагментов текста предназначены комбинации от \$1 до \$9, где цифра указывает порядковый номер выражения в скобках в строке поиска. Таким образом, поиску комбинации «цифра-тире-цифра» будет соответствовать выражение ([0-9])-([0-9]), или — (\d)-(\d) (спецсимвол d — сокращение от digital), а замена в ней дефиса на тире будет выглядеть как \$1-\$2. Все заменяемые выражения окружаются кавычками и соединяются в цепочку через «+». На этом мы заканчиваем с теорией и переходим к практике…
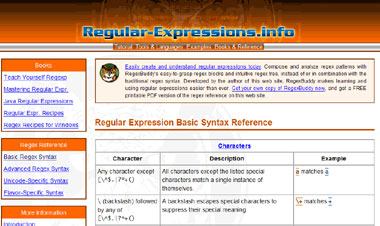 |
| На самом деле возможности регулярных выражений ещё мощнее, чем описано в статье. Интересующиеся могут познакомиться с ними на сайте http://www.regular-expressions.info/reference.html |
Практика
Давайте составим список необходимых операций поиска-замены:
- Несколько подряд идущих пробелов заменить на один.
- Между числами поставить неразрывное тире.
- Вокруг тире - только неразрывные пробелы.
- Пробел после цифры - неразрывный (например, "3 кг").
- кв.м и куб.м - м╡ и мЁ.
- Несколько подряд идущих прописных букв (часто используются для обозначения формы собственности предприятия) не отрывать от последующего слова (например, АОЗТ "Пластмассы").
- Кроме того, в списках для их отбивки по левому краю после пробела будем вставлять символ Indent Here.
JavaScript по шагам
1. Для замены двух и более пробелов на один потребуется ещё немного расширить наши познания в регулярных выражениях. Для поиска текстового фрагмента заданной длины в них предусмотрена конструкция «{min, max}», определяющая минимально и максимально допустимую длину поискового фрагмента. В нашем случае достаточно составить конструкцию {2,} — неуказанный явно второй аргумент говорит о том, что максимум не ограничен, что и требуется. Меняем на один пробел (« »).
2. Для реализации второго условия подойдёт строка (\d)-(\d), но для расширения функционально-сти её лучше заменить на (\d) ?-|— ?(\d). Это позволит расширить охват: будем искать числа, после которых может быть пробел (в подаваемом на вёрстку материале случается всякое), затем стоит либо «-» либо «—», после чего опять же возможен пробел и, наконец, снова идёт цифра. Таким образом, мы вовлекаем в диапазон поиска значительно большее количество вариантов написания, и замена будет универсальнее. Скобки нужны для сохранения результатов поиска при последующей замене.
Строка замены будет выглядеть как “$1” + “\u2011” + “$3”. Она означает, что заменяемое выражение будет состоять из числа, найденного первым (которое в первых скобках, соответствует “$1”), после чего вставляем неразрывное тире и дописываем второе найденное число (“$2”). Код неразрывного тире (как и любого символа) находится несколькими способами. Самый надёжный — в начале любого абзаца вставить необходимый символ, выделить его и использовать вспомогательный скрипт: alert(app.selection[0].paragraphs[0].charCodeAt[0]). Есть информация, что в обновлённой версии дополнительного модуля JavaScript возможность изъята; я тестировал оригинальную сборку, идущую в поставке с CS2.
Функция alert выдаёт сообщение, а charCodeAt как раз и даст нам код, используемый в InDesign для неразрывного тире (2011). В selection используется ссылка на начальный объект [0], т. к. область выделения — не конкретный объект, а массив (в него может входить все что угодно, не только текст; и хотя в нашем случае ничего другого в выделении нет, мы обязаны указать InDesign, что нас интересует именно первый объект в семействе selection). Поскольку код выдаётся в Unicode (для универсальности), мы это отмечаем, помещая впереди комбинацию «\u» (Unicode).
3. Точно так же для третьей замены меняем обычные пробелы вокруг тире на неразрывные (их 16-ричный код «A0» предваряется ключом \х).
В четвёртом шаге для замены пробела после числа на неразрывный используем комбинацию «\d » — строка замены будет “$1”+”\xA0”. Но после чисел могут стоять множители (тыс., млн, млрд), поэтому для корректной обработки связки «число-множитель-размерность» можно воспользоваться такой цепочкой действий: сначала привяжем к цифрам размерности, а потом — сами множители. В результате для поиска получим:
find1 = \d ; find2 = (тыс|млн|млрд)\.? ?;
Независимо от того, стоит после множителя точка и/или пробел, мы будем корректно отрабатывать все комбинации. В этом и состоит главная прелесть регулярных выражений — они дают чрезвычайную гибкость в поиске нужных фрагментов. Строка замены в таком случае будет иметь вид:
replace1 = $1+\xA0 replace2 = $1+\.\xA0
Напомню, «\xA0» — 16-ричное значение неразрывного пробела, а «\.» — точка (знак «\» перед ней стоит, чтобы не было путаницы с «.» — подстановочным знаком для любого символа). Кстати, чтобы сочетания «м╡», «мЁ» обрабатывались корректно (после цифры оставался обычный пробел), исключим из диапазона захвата сочетание «м, идущее перед цифрой». В результате find1 изменится на ([^м])(\d) , а replace1 — на “$1”+”$2”+”\xA0”.
5. Следующий шаг — сокращения типа АО, ЗАО, АОЗТ и пр. Чтобы не отрывать форму собственности от самого названия, достаточно указать минимальную длину искомой конструкции — 2. Поиск ведём только среди прописных букв (А-Я). В результате для поиска получим: ([А-Я]{2,}) ("|"), уточнение ("|") внесено для большей гибкости после апробации на реальных текстах, учитывает наличие кавычек в названии организаций.
6. Следующий шаг не относится непосредственно к теме поиска/замены, но упрощает работу со списками. Предусмотрим автоматическое добавление символа левой границы текста (Indent here) по пробелу, следующему сразу за отбивочным знаком списка, т. е. ищем выражение ^[\x95\u2013\u2014\x2D]. Знак «^» обеспечивает поиск только в начале строк, \x95, \u2013, \u2014 и \x2D — варианты отбивки (пуля, табуляция, длинное тире либо дефис). Замена — на “$1” + “\u2002” + “\x07”, где “\u2002” + “\x07” — коды пробела фиксированной ширины и «Indent here», соответственно. Определение значений всех спецсимволов через дополнительный скрипт и выделение были описаны ранее.
7. Последний шаг — перевод выражений «кв.м», «куб.м» в принятую форму (м╡, мЁ). Разобьём его на два этапа: сначала проводим замену «кв.» и «куб.» на соответствующие цифры, затем переводим их в надстрочный индекс. С учётом всевозможных модификаций написания (с точкой и без, с пробелом и без между словами) получим строку поиска кв[\. ?](м)[\. ?]. Следующий шаг — поиск выражений «м╡» и «мЁ» и замена стиля форматирования для цифры.
Итак, основная работа выполнена. Осталось только оформить наши записи в виде скрипта. Регулярные выражения в Javascript задаются между двумя косыми чертами (слэшами), а ключ «g» означает многократную замену (global). Также предусмотрен ключ «i» — игнорирование регистра (т. е. менять и строчные, и прописные), но нам он не понадобится. Поиск будем проводить по очереди в каждом абзаце выделенного текстового фрагмента. Итак, можем записать для блока базовых преобразований:
find1 = / {2,}/g; replace1 = " "// замена множества пробелов find2 = /(\d) ?(-|-) ?(\d)/g; replace2 = "$1" + "\u2011" + "$3"// неразр. тире между цифрами, удаление лишних пробелов find3 = /(.) (-|-) (.)/g; replace3 = "$1" + "\xA0" + "\u2013" + "\xA0" + "$3"//неразр.пробелы вокруг тире find40 = /([^м])(\d) /g; replace40 = "$1"+ "$2"+ "\xA0"//пробел после числа - неразрывный find41 = /(тыс|млн|млрд)\.? ?g; replace41 = "$1"+ "\.\xA0"//учиты ваем множители
Остальные операции поиска/замены:
find5 = /([А-Я]{2,}) ("|")/g replace5 = "$1"+ "\xA0"+ "$2" // не отрывать форму собственности от названий find6 = /^([\x95\u2013\u2014\x2D])/g; replace6 = "$1" + "\u2002" + "\ x07"//в списке - фикс.пробел + indent here find7 = /кв[\. ?](м)/g; replace7 = "$1"+ "2" find8 = /м[23]/;
 |
| Результат работы скрипта |
Объединяя JavaScript и InDesign | С инструментарием JavaScript закончили, вернёмся к возможностям InDesign. Определим диапазон поиска. Логично проводить его только в текстовых абзацах, игнорируя таблицы и иллюстрации (заставить скрипт искать в таблицах не составляет труда, но это материал для другой статьи). Необходимо учитывать и наличие сносок, поскольку InDesign некорректно обрабатывает поиск в них. Анализ объектной модели программы показал, что в параметрах абзаца предусмотрены свойства tables (наличие таблиц), allGraphics (иллюстраций) и сносок (footnotes), чем мы и воспользуемся.
Проводим замены по очереди в каждом выделенном абзаце, для чего воспользуемся методом replace, применённым к свойству contents (содержимое в виде строки) абзаца.
pars = app.selection[0].paragraphs for (i=0; i
По окончании заменяем прежнее содержимое абзаца новым:
pars[i].contents = r
Теперь перейдём к переводу цифр в верхний регистр. Напрямую уже использовавшимся методом replace воспользоваться не удастся (JavaScript работает только с неформатированным текстом), поэтому с его помощью найдём позицию сочетаний м╡ и мЁ, после чего перейдём к возможностям форматирования InDesign. Будем использовать метод search (поиск), который выдаёт позицию символа, удовлетворяющего условию поиска. В нашем случае он найдёт позицию сочетания м╡ от начала абзаца. Соответственно позиция цифры будет больше найденного значения на 1, после чего нам останется применить к символу метод перевода в верхний регистр position. Поиск продолжаем до тех пор, пока результат поиска не станет «-1» (ничего не найдено).
do { ix = pars[i].contents.search(find8) if(ix != -1) pars[i].characters[ix+1].position = Position.superscript } while (ix != -1) } }
Общие замечания | Вот и весь скрипт. При запуске для объёмных публикаций результатов придётся немного подождать, но если текст перед вёрсткой вычитывается, то некоторые операции замены можно исключить (например, поиск многократных пробелов), что положительным образом отразится на скорости работы. Среди плюсов предложенного решения — компактность и лёгкость добавления собственных правил обработки текста.
И последнее: выделение я использую для гибкости — чтобы можно было отдать подготовленный раздел публикации, как только закончена работа над ним (для оперативности разделы по мере их подготовки выкладываются на сервере в виде PDF), вместо ожидания окончания работы над всем изданием. Вам же, возможно, больше понравится обработка всего документа — это нетрудно сделать добавлением в скрипт нескольких строк.
Ищем и меняем средствами InDesign
В пакете предусмотрена поддержка операций поиска/замены через метод search.
Среди его параметров — искомая строка, чувствительность к регистру, заменяющий текст, атрибуты поискового фрагмента и заменяющего (в т. ч. их форматирование).
Для удобства атрибуты задаются в виде отдельных наборов Find Preference и Change Preference (c точки зрения InDesign — отдельные объекты), в которых перечисляются все необходимые параметры. Среди них — любые допустимые параметры абзаца, в т. ч. стиль отдельного символа (character). Таким образом, сформировав необходимое количество наборов, можно по очереди проводить поиск и замену.
Как это делать
1. Писать скрипт можно в любом текстовом редакторе. Но чтобы пользоваться отладчиком (ошибки будут всегда, особенно на стадии изучения, а отладчик позволяет запустить скрипт пошагово и быстро локализовать проблему), файлу нужно дать расширение jsx — с ним в Creative Suite 2 ассоциирован ExtendScript Editor, устанавливающийся с любым ПО от Adobe. Если используется Creative Suite первой версии, то расширение «js» на «jsx» менять не нужно, а вот добавление в скрипт строчки «$.level = 1» позволит отладчику остановиться в указанном вами месте (его помечают через $.bp()).
К слову сказать, отладчик в новой версии мощнее, пользоваться им удобнее, поэтому настоятельно рекомендую именно Creative Suite 2.
2. При активном тестировании может возникнуть ситуация, когда скрипт начинает сбоить, т. е. выдавать ошибку там, где её на самом деле нет. Как правило, это происходит при повторном применении скрипта к одному документу. Память «засоряется» историей ваших ошибок, поэтому желательно тестовый файл перед повторным запуском скрипта закрыть (в этом случае память очищается) и вновь открыть. Конечно, при интенсивном тестировании это раздражает, а определить, что скрипт действительно работает некорректно, уже невозможно. Поэтому возьмите за правило заново открывать файл через несколько запусков скрипта. Если же скрипт вообще начинает «спотыкаться на ровном месте», перезагрузите отладчик и, желательно, само хост-приложение.
3. Для удобства в левом окне отладчика (панель Data Browser) отображаются текущие значения всех используемых переменных, что позволяет следить за ними без дополнительных действий. Если потребуется узнать какое-то конкретное значение, можно вписать необходимую строчку в верхнем окне панели JavaScript Console.
И напоследок. Перед запуском скрипта в отладчике проверьте, какое хост-приложение выбрано в качестве рабочего (панель Target Application). По умолчанию отладчик настроен на ExtendScript ToolKit, поэтому будьте бдительны.
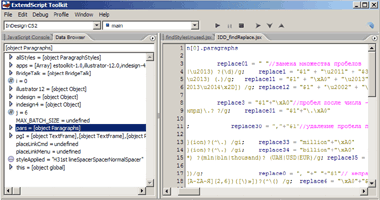 |
| ExtendScript Editor — удобный инструмент поиска проблемных участков кода |
Два совета
1. Вместо перечисления всех операций поиска/замены (r = r.replace(find, replace)), можно воспользоваться возможностями массивов: записывать строки поиска/замены сразу как элементы массива, а потом в цикле перебирать их, что сократит объём кода и повысит его читабельность.
2. Иногда InDesign путается: как вы, наверное, заметили, метод search существует и в собственном обработчике сценариев пакета, и в JavaScript. Тогда он выдаёт ошибку: некорректный вызов метода «search» (параметры у каждого обработчика свои). Попробуйте перезапустить приложение — очень часто помогает.
Удаляем неиспользумые стили
Возможности регулярных выражений не исчерпываются только поиском в тексте, их можно творчески расширить. Вот пример использования регулярных выражений для удаления из публикации неиспользованных стилей. Подход следующий: сначала просматриваются по очереди все абзацы и определяются задействованные стили (используется свойство абзаца appliedParagraphStyle). Названия стилей записываются в строку. Также по очереди выбираются стили из списка всех существующих в публикации (у неё есть свойство document.paragraphStyles), после чего названия сравниваются: если стиль из списка найден в сформированной строке, то переходим к следующему, если нет — значит, в публикации он не используется и потому удаляется.
Чтобы охватить всё содержимое полосы (в т. ч. «заякоренные» текстовые блоки Anchor, согласно объектной модели, не входящие в состав текстового фрейма, которому они принадлежат), будем искать абзацы через свойство allPageItems. Оно даёт доступ ко всему содержимому полосы.
Создаём ссылки на объекты:
pgI = document.allPageItems; allStyles = document.paragraphStyles;//все хранимые стили
Создаём строку для накопления в ней всех использованных в документе стилей:
styleApplied = “ “;
В цикле просматриваем содержимое каждой страницы, отфильтровываем только текстовые фреймы и сохраняем все использованные стили:
for (i=0; i
Сравниваем хранимые в публикации стили с используемыми. Учитываем, что в InDesign существует два предопределённых стиля, которые не могут быть удалены (No Paragraph Style и Basic Paragraph), а потому сразу исключаем их из проверки (начинаем со стиля с индексом 2, т. к. счёт начинается с «0»):
for (i=2; i
Если стиль не найден, удаляем его и учитываем это в счётчике:
if (ix == -1) { allStyles[i].remove(); i-} }
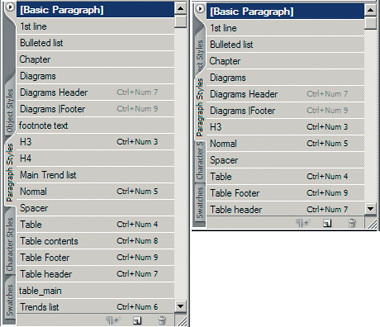 |
| Результат работы скрипта: до(слева) и после (справа) |
Пользуйтесь на здоровье!





/13259286/i_380.jpg)
/13259285/i_380.jpg)
/13259371/i_380.jpg)
/13259298/i_380.jpg)