.png)
.png)
.png)
В 2007 г. версия CS3 преподнесла нам много приятных сюрпризов, в т. ч. поддержку регулярных выражений при поиске и замене, а CS4 пошла ещё дальше. Чем же они могут быть полезны?
Введение
Регулярные выражения (Regular Expression, RegExp) имеют длинную историю. Они применялись ещё в 70-х годах в текстовом редакторе Ed в системе UNIX, позже — в Perl, Apache, PHP, InDesign. Особенно эффективны при выполнении поиска и замены.
В отличие от обычного поиска, где указывается конкретный текст, регулярные выражения позволяют обобщить условия поиска с помощью системы шаблонов. Шаблоны — это текстовые фрагменты (обычные символы и метасимволы), с помощью которых задаются специальные функции: альтернативные варианты поиска, условия повторений и пр. Интересующимся рекомендую ссылки в конце статьи, а здесь разберу задачи, которые помогут понять работу системы шаблонов и пригодятся при работе с текстом в InDesign.
Для выполнения всех задач используется операция Edit•Find/Change (Поиск и замена) и закладка GREP (регулярные выражения).
Задача № 1. Автоматическая расстановка переносов в текстах, содержащих кириллицу и латиницу
Для работы системы переносов нужно в параметрах символов задать для кириллицы русский язык, а для латиницы — английский. Делать это вручную весьма трудоёмко.
Решение:
в строке поиска задать: [a-zA-Z]; в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать нужный язык: английский.
Объяснение
Вначале следует выделить весь текст и задать для него русский язык.
Затем выполнить поиск всех символов латиницы и задать для них английский язык. Для этого в строке поиска ввести шаблон альтернативного выбора символа, который выглядит как набор символов, заключённый в квадратные скобки. Так, шаблон [abc] ищет символы «a», «b» или «с», шаблон [0-9] — все цифры, а для поиска всех символов латиницы зададим шаблон [a-zA-Z] — в нём перечисляются символы в нижнем и верхнем регистрах. А вот так выглядит шаблон для поиска символов кириллицы: [а-яА-Я]. И всё! Рис. 1 поясняет пример.
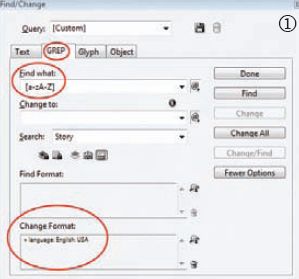
Задача № 2. Поиск слова и всех его форм
Например, для задания оформления полужирным. Решим эту задачу для слова «пример».
Решение:
в строке поиска задать: \<(?i) приме(р|ры|ров|ре|ра)\>; в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать оформление полужирным.
Объяснение
Во-первых, нужно определить все формы этого слова. В нашем случае это будут: «пример», «примеры», «примеров», «примера», «примеру», «примере» (кроме «например», «примерный» и пр. — это уже другие слова).
На этот раз нам нужно задать альтернативные варианты не для символов, а для слов. Такая возможность в шаблонах предусмотрена и реализуется перечислением через символ «|» (вертикальная черта). То есть строка поиска должна содержать:
«пример|примеры|примеров|примере|примера»
Однако такой поиск игнорирует слова с заглавной буквы! Чтобы решить эту проблему, нужно в строку поиска ввести метасимвол (?i), который заставит при поиске игнорировать регистр. И теперь строка поиска выглядит так: «(?i)пример|примеры|примеров|примере|примера». Не беспокойтесь, при замене регистр будет сохранён.
Но есть другая проблема — система находит эти слова внутри других слов («например», «примерный» и пр.), а нам это не нужно! Выход — надо искать слово целиком. Для этого следует обозначить границы слова в строке поиска — начало и конец слова обозначаются метасимволами \< и \>. Теперь строка поиска выглядит так: \<(?i)пример|примеры|примеров|примере|примера\>
Это уже готовое решение, но его можно записать значительно проще! Чтобы отделить меняющуюся часть слова от неизменной, используем группировку символов, для чего альтернативные варианты укажем в круглых скобках: приме(р|ры|ров|ре|ра).
Теперь всё работает как нужно — задача решена!
Задача № 3. Поиск текста в кавычках, включая кавычки.
Например, для оформления курсивом. Это могут быть названия картин («Мечта рыбака») и т. п.
Решение:
в строке поиска задать: «.+?»; в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать оформление курсивом.
Объяснение :
Строка поиска должна начинаться и заканчиваться кавычками. А что между ними? Да что угодно! Для его обозначения используются метасимволы, а для задания количества — квантификаторы. Если известно, что внутри кавычек содержится 5 символов, строка поиска должна выглядеть так: «\w\w\w\w\w». А если неизвестно? Тогда нам помогут квантификаторы — метасимволы, задающие число повторений. Они указываются после символа или метасимвола.

Кажется, что нам подойдёт комбинация «\w+». Но в ней не учитывается наличие пробелов внутри и то, что система может найти текст не до первой закрывающей кавычки, а, например, до второй. Чтобы найти текст только между соседними кавычками, используем короткий вариант: «\w+?». А чтобы найти ещё и пробел (\s) внутри, зададим альтернативу: «[\w\s]+?».

Почти всё правильно, но вот название «Гуси-лебеди» наш поиск проигнорирует… Расширим до максимума набор допустимых символов — используем метасимвол «точка» (.) и получим: «.+?». Это и есть долгожданное решение!
Информация для размышления: а если, помимо названий картин, в тексте содержатся цитаты и прочие длинные тексты в кавычках? Пока подумайте сами! А решение ищите в конце статьи…
Задача № 4. Поиск текста в кавычках, НЕ включая сами кавычки.
Например для оформления подчёркиванием — «Мечта рыбака».
Решение: в строке поиска задать: (?<=«).+?(?=»); в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать оформление подчёркиванием.
Объяснение
Нам нужно найти текст в кавычках, но не нужно воздействовать на сами кавычки. Для этого в системе шаблонов есть возможности просмотра текста: впереди (?<=) и позади (?=). Просматриваемые символы указываются внутри скобок. Символы, указываемые в шаблоне просмотра, не войдут в результат поиска.
Таким образом, строка поиска вместо «.+?» будет выглядеть так: (?<=«).+?(?=»).
Задача № 5. Соединение фамилии и инициалов неразрывным пробелом
Решение:
в строке поиска задать: (\u[А-Яа-я-]+)\s(\u.)\s(\u.); в строке замены задать: $1~S$2~S$3.
Объяснение
Такого типа задачи проще всего решать за счёт начального разбиения и последующей компоновки. В шаблонах можно запоминать результаты поиска. Искомые фрагменты указываются в строке поиска в круглых скобках, а в строке замены к содержимому скобок можно обратиться указанием $1 (первые скобки) и до $9 (в InDesign доступно 9 фрагментов) и скомпоновать с их помощью нужный фрагмент.
Учтём, что фамилия начинается с заглавной буквы, а инициалы состоят из заглавных букв, разделённых точкой и пробелом: «Иванов А. Б.» или «Миклухо-Маклай Н. Н.» Шаблон поиска может выглядеть так: \u[А-Яа-я-]+\s\u.\s\u.. То есть вначале ищем заглавную букву \u, затем ищем комбинацию букв [А-Яа-я-]+, затем инициалы \s\u.\s\u..
Но как сюда добавить неразрывный пробел? Используем запоминание результатов — элементы шаблона заключим в круглые скобки: (\u[А-Яа-я-]+)\s(\u.)\s(\u.). Результат поиска для первых скобок (\u[А-Яа-я-]+) будет помещён в $1 (фамилия), вторых скобок (\u.) — $2, третьих (\u.) — $3.
А для компоновки результата в строке замены укажем $1~S$2~S$3 (~S — это неразрывный пробел).
Задача № 6. Поиск и оформление e-mail
Решение:
в строке поиска задать: [\l\u\d\._%-]+@[\l\u\d\._%-]+; в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать нужное оформление.
Объяснение
Здесь \l\u\d означает буквы в верхнем и нижнем регистре и цифры, а \._%- — это символы, допустимые в адресах. Символ «точка» обозначается в строке поиска \., так как написание . является не «точкой», а метасимволом (см. задачу № 3).
Задача № 7. Поиск и оформление url (адреса в интернет)
Решение:
в строке поиска задать: (((ht|f)tps?://|(www|ftp)\.)[^\s\n]+)(?<![\[\]\.,:;!\}\)<-]); в строке замены ничего не задавать или ввести в неё $0 (означает найденный текст); в опциях замены указать нужное оформление.
Объяснение
Фрагмент (ht|f)tps?:// ищет название протокола: «http://», «https://», «ftp://». Помните, что s?: означает, что «s» может быть, а может и не быть.
Фрагмент (www|ftp)\. ищет начальные символы адреса — «www.» или «ftp.». Таким образом, фрагмент ((ht|f)tps?://|(www|ftp)\.) ищет начало адреса URL (типа «http://www.», «www.», «http://»).
Затем фрагмент [^\s\n]+ ищет любые символы, кроме пробелов (\s) и перевода строк (\n). Таким образом, фрагмент (((ht|f)tps?://|
(www|ftp)\.)[^\s\n]+) ищет уже полноценный адрес, но захватывает и символ справа от него — точку, запятую и прочее. Чтобы исключить это ненужное, используется фраза (?<![\[\]\.,:;!\}\)<-]), которая убирает любой из символов «[].,;!}<-». Обратите внимание, что вместо обычного написания некоторых («.») используется \. — это нужно потому, что эти символы при обычном написании выполняют роль метасимволов. А чтобы вернуть роль обычных символов, их записывают через \.
Заключение
Регулярные выражения очень удобно использовать в скриптах — это позволяет автоматизировать обработку текста. А в CS4 их можно использовать даже в параметрах абзаца, чтобы задавать оформление «на лету»!
Примечание
Решение задачи № 3: «.{3,30}» — задаём длину строки от 3-х до 30-ти символов, отсекая длинные фрагменты.
Об авторе: Юрий Павлов (http://yuri-pavl.com), ведущий преподаватель Центра компьютерного обучения «Специалист» при МГТУ им. Н. Э. Баумана. Первым в России получил статусы Adobe Certified Expert, Adobe Certified Instructor, Corel Certified Expert, Corel Certified Instructor.
Полезные ссылки
http://ru.wikipedia.org/wiki/Регулярные_выражения
http://regexp.ru/
http://livedocs.adobe.com/en_US/InDesign/5.0/
http://www.rorohiko.com/greptutor/GrepTutor.html

.jpg)



/13269431/i_380.jpg)
/13269462/i_380.jpg)
/13269315/i_380.jpg)
/13269313/i_380.jpg)